Scheduling Web Scrapers on the PythonAnywhere Cloud (Scrapy Part 2)
(Note: This post is part of my reddit-scraper series)
Summary
- Running Scrapy spider as a script
- Scheduling script to run on PythonAnywhere cloud
Previously on Siv Scripts, we created a web scraping pipeline to pull Top Posts from Reddit and store them in a MongoDB collection. At this stage, we still have to manually execute our crawler via the command-line interface (CLI) each time we want to scrape Reddit.
Cue Raymond Hettinger: There MUST be a better way!
And there is!
In this post, we will convert our command-line Scrapy application into a script that we will schedule to run on the Python Anywhere cloud platform. In addition, we will use our top_post_emailer module to automatically send ourselves an email digest of the data that was scraped.
What You Need to Follow Along
Development Tools (Stack)
- Python 3.5
- PythonAnywhere account
- MongoDB
- Cloud accessible installation -- MLab
- Free Sandbox plan provides single database with 0.5 GB storage on a shared VM
- MailGun account
- Free account is limited to 10K emails per month, more than enough for our purposes
Code
- Github Repo - Tag: blog-scrapy-part2
We can checkout the code from the git repository as follows:
$ git checkout tags/blog-scrapy-part2
Note: checking out 'tags/blog-scrapy-part2'.
Or we can use GitZip to download the tagged commit by URL.
Setting up MongoDB on mLab
Up until now we have been using a local instance of MongoDB to store our scraped data. Since we will be running our scraper on the cloud, we will also need to create an online instance of our database where we can store data.
Head over to mLab to create an account and set up a collection in our sandbox database to store the data.
Let's initialize our MongoDB collection with documents from our local collection. From the MongoDB docs:
$ mongoexport --db sivji-sandbox --collection top_reddit_posts --out 20170322-reddit-posts.json
2017-03-22T23:18:39.404-0500 connected to: localhost
2017-03-22T23:18:39.429-0500 exported 751 records
$ mongoimport -h <mlab-url>:port -d sivji-sandbox -c top_reddit_posts -u <dbuser> -p <dbpass> --file 20170322-reddit-posts.json
2017-03-22T23:21:14.075-0500 connected to: <mlab-url>:port
2017-03-22T23:21:15.504-0500 imported 751 documents
We can use MongoDB Compass to view our mLab instance and create indexes for our collection. I covered how to do this in a previous post.
Running Scrapy From a Script
Currently we run our spider using the scrapy crawl command via Scrapy's CLI. Looking through the Scrapy documentation, we see that we can utilize Scrapy's API and run our scraper as a script.
In our Scrapy directory, let's add the following file:
# app.py (v1)
"""Script to crawl Top Posts across sub reddits and store results in MongoDB
"""
from scrapy.crawler import CrawlerProcess
from reddit.spiders import PostSpider
if __name__ == '__main__':
process = CrawlerProcess(get_project_settings())
process.crawl(PostSpider)
process.start() # the script will block here until the crawling is finished
Let's also take this opportunity to modify our Scrapy project to use our mLab MongoDB instance. This will require us to change the following files:
# settings.py
import os
import configparser
# ...
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'reddit.pipelines.MongoPipeline': 300,
}
## get mongodb params (using configparser)
config = configparser.ConfigParser()
config.read(os.path.join(os.path.abspath(os.path.dirname(__file__)), 'settings.cfg'))
mlab_uri = config.get('MongoDB', 'mlab_uri')
MONGO_URI = mlab_uri
MONGO_DATABASE = 'sivji-sandbox'
# ...
# top_post_emailer/settings.cfg
[MongoDB]
mlab_uri = [Your mLab URI here]
Our Scrapy project folder should have the following structure:
.
├── app.py
├── reddit
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.cfg
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg
We can execute our Reddit Top Posts scraper as a script by running app.py in a Python interpreter.
Aside: Testing Web Scrapers
How should we test web scrapers?
We could download an offline copy of the webpage we are scraping and use that to test changes to our parse() method. Let's think about this a bit more: what happens if the website changes its layout and our offline copy becomes stale? A StackOverflow (Praise Be) user suggested a good workflow for this situation.
We could also consider utilizing Spider contracts to check if we are getting expected results for a specified URL. Be aware of the limitations and issues with contracts.
We will not be implementing any kind of unit tests for this scraper. The Reddit layout is more-or-less static. If the website changes, we will notice this in the email digests we receive and we can make the necessary modifications at that time. For projects that are a bit more critical than our toy scraper, we should probably set up unit tests as described above.
import Email Functionality
In a previous post, we created the top_post_emailer to send ourselves email digests. Let's import this package and wire it into our script.
If you followed the previous post, copy the top_post_emailer folder into the Scrapy project folder. If you do not already have this package, you can download this folder from Github using GitZip and extract it into the Scrapy project folder.
Since we are using mLab as our database, we will need to update the following files:
# top_post_emailer/__init__.py
import os
import configparser
from mongoengine.connection import connect
from .data_model import Post
from .render_template import render
from .mailgun_emailer import send_email
def email_last_scraped_date():
## mongodb params (using configparser)
config = configparser.ConfigParser()
config.read(os.path.join(os.path.abspath(os.path.dirname(__file__)), 'settings.cfg'))
mlab_uri = config.get('MongoDB', 'mlab_uri')
# connect to db
MONGO_URI = mlab_uri
connect('sivji-sandbox', host=MONGO_URI)
## get the last date the webscraper was run
for post in Post.objects().fields(date_str=1).order_by('-date_str').limit(1):
day_to_pull = post.date_str
## pass in variables, render template, and send
context = {
'day_to_pull': day_to_pull,
'Post': Post,
}
html = render("template.html", context)
send_email(html)
# top_post_emailer/settings.cfg
[MailGun]
api = [Your MailGun API key here]
domain = [Your MailGun domain here]
[MongoDB]
mlab_uri = [Your mLab URI here]
Let's add email functionality to our script:
# app.py (v2 - final version)
"""Script to crawl Top Posts across sub reddits and store results in MongoDB
"""
import logging
from datetime import date
from scrapy.utils.project import get_project_settings
from scrapy.crawler import CrawlerProcess
from reddit.spiders import PostSpider
from top_post_emailer import email_last_scraped_date
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# only run on saturdays (once a week)
if date.strftime(date.today(), '%A').lower() == 'saturday':
crawler = CrawlerProcess(get_project_settings())
crawler.crawl(PostSpider)
crawler.start() # the script will block here until the crawling is finished
email_last_scraped_date()
logger.info('Scrape complete and email sent.')
else:
logger.info('Script did not run.')
Note
- We used the Python
loggingmodule to provide additional details on the innerworkings of our application. Another fantastic tool available in the Python Standard Library. Batteries are included
PythonAnywhere
In this section we will explore the PythonAnywhere cloud platform, set up a Python virtual environment for our scraper, and configure the PythonAnywhere scheduler to run our Scrapy script.
Overview
PythonAnywhere makes it easy to create and run Python programs in the cloud. You can write your programs in a web-based editor or just run a console session from any modern web browser. There's storage space on our servers, and you can preserve your session state and access it from anywhere, with no need to pay for, or configure, your own server. Start work on your work desktop, then later pick up from where you left off by accessing exactly the same session from your laptop.
What does this mean? For 5 bucks a month, we can host websites and schedule batch jobs in a fully configurable Python environment.
More information can be found on their website and Episode 10 of the Talk Python to Me podcast.
Setting Up Environment
After you create an account, you will need to open up a Bash console:
virtualenv and pip
Now we will set up a virtualenv and pip install required packages:
11:06 ~ $ mkvirtualenv scrapy36 --python=/usr/bin/python3.6
Running virtualenv with interpreter /usr/bin/python3.6
Using base prefix '/usr'
New python executable in /home/pythonsivji/.virtualenvs/scrapy36/bin/python3.6
Also creating executable in /home/pythonsivji/.virtualenvs/scrapy36/bin/python
Installing setuptools, pip, wheel...done.
virtualenvwrapper.user_scripts creating /home/pythonsivji/.virtualenvs/scrapy36/bin/predeactivate
virtualenvwrapper.user_scripts creating /home/pythonsivji/.virtualenvs/scrapy36/bin/postdeactivate
virtualenvwrapper.user_scripts creating /home/pythonsivji/.virtualenvs/scrapy36/bin/preactivate
virtualenvwrapper.user_scripts creating /home/pythonsivji/.virtualenvs/scrapy36/bin/postactivate
virtualenvwrapper.user_scripts creating /home/pythonsivji/.virtualenvs/scrapy36/bin/get_env_details
(scrapy36) 11:08 ~ $ which python
/home/pythonsivji/.virtualenvs/scrapy36/bin/python
(scrapy36) 11:08 ~ $ pip install scrapy mongoengine jinja2 requests
Collecting scrapy
Downloading Scrapy-1.3.3-py2.py3-none-any.whl (240kB)
100% |████████████████████████████████| 245kB 2.2MB/s
Collecting mongoengine
Downloading mongoengine-0.11.0.tar.gz (352kB)
100% |████████████████████████████████| 358kB 1.8MB/s
Collecting jinja2
Collecting requests
... additional rows ommitted ...
Additional Resources
Uploading code into PythonAnywhere
There are many ways to get code in and out of PythonAnywhere. We will be uploading our local project folder to Github and then cloning our repo into PythonAnywhere as follows:
(scrapy36) 23:50 ~ $ mkdir siv-dev && cd siv-dev
(scrapy36) 23:51 ~/siv-dev $ git clone https://github.com/alysivji/reddit-top-posts-scrapy.git
Cloning into 'reddit-top-posts-scrapy'...
remote: Counting objects: 63, done.
remote: Compressing objects: 100% (23/23), done.
remote: Total 63 (delta 9), reused 0 (delta 0), pack-reused 39
Unpacking objects: 100% (63/63), done.
Checking connectivity... done.
Notes
- Creating a git repo is not covered here. There are plenty of online resources available that cover this topic in the requisite detail. Relevant xkcd
- Make sure you add
settings.cfgto your.gitignorefile if you are using a public repo. In this case, you will need to manually upload thesettings.cfgfiles into their respective folders
Set up Scheduler
In order to run a scheduled task in a virtualenv, we require the full path to the virtualenv's Python. We can get this as follows:
(scrapy36) 23:52 ~/siv-dev/reddit-top-posts-scrapy (master)$ which python
/home/pythonsivji/.virtualenvs/scrapy36/bin/python
(scrapy36) 23:54 ~/siv-dev/reddit-top-posts-scrapy (master)$ pwd
/home/pythonsivji/siv-dev/reddit-top-posts-scrapy
Now we will create a bash script to cd into our project directory and execute the Scrapy script:
# ./run_reddit_scraper
#!/bin/bash
# scrapy project files require us to be in the project folder to load settings
# run with scrapy virtualenv
cd /home/pythonsivji/siv-dev/reddit-top-posts-scrapy/
"/home/pythonsivji/.virtualenvs/scrapy36/bin/python" app.py
In the console, we will need to change permissions to make our newly-created file executable:
$ chmod 755 run_reddit_scraper
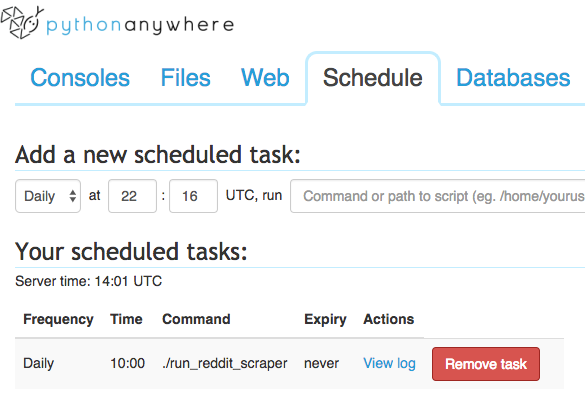
Next, we schedule the following command to run Daily at 10:00 UTC:
./run_reddit_scraper
The Schedule dashboard should look as follows:
Monitoring Runtime
Let's take a look at the log to make sure everything is working:
... additional rows omitted ...
DEBUG:root:Post added to MongoDB
2017-04-01 14:45:29 [root] DEBUG: Post added to MongoDB
DEBUG:scrapy.core.scraper:Scraped from <200 https://www.reddit.com/r/MachineLearning/top/?sort=top&t=week>
{'commentsUrl': 'https://www.reddit.com/r/MachineLearning/comments/61kym3/p_poker_hand_classification_advice_needed/',
'date': datetime.datetime(2017, 4, 1, 14, 45, 29, 385712),
'date_str': '2017-04-01',
'score': 24,
'sub': 'MachineLearning',
'title': '[P] Poker hand classification, advice needed',
'url': 'https://www.reddit.com/r/MachineLearning/comments/61kym3/p_poker_hand_classification_advice_needed/'}
INFO:scrapy.core.engine:Closing spider (finished)
2017-04-01 14:45:29 [scrapy.core.engine] INFO: Closing spider (finished)
2017-04-01 14:45:29 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 2388,
'downloader/request_count': 7,
'downloader/request_method_count/GET': 7,
'downloader/response_bytes': 101355,
'downloader/response_count': 7,
'downloader/response_status_count/200': 5,
'downloader/response_status_count/301': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 4, 1, 14, 45, 29, 398366),
'item_scraped_count': 100,
'log_count/DEBUG': 208,
'log_count/INFO': 7,
'response_received_count': 5,
'scheduler/dequeued': 6,
'scheduler/dequeued/memory': 6,
'scheduler/enqueued': 6,
'scheduler/enqueued/memory': 6,
'start_time': datetime.datetime(2017, 4, 1, 14, 45, 26, 699177)}
INFO:scrapy.core.engine:Spider closed (finished)
2017-04-01 14:45:29 [scrapy.core.engine] INFO: Spider closed (finished)
DEBUG:requests.packages.urllib3.connectionpool:Starting new HTTPS connection (1): api.mailgun.net
2017-04-01 14:45:29 [requests.packages.urllib3.connectionpool] DEBUG: Starting new HTTPS connection (1): api.mailgun.net
DEBUG:requests.packages.urllib3.connectionpool:https://api.mailgun.net:443 "POST /v3/sandbox024e4bcae7814311932f6e9569cea611.mailgun.org/messages HTTP/1.1" 200 138
2017-04-01 14:45:30 [requests.packages.urllib3.connectionpool] DEBUG: https://api.mailgun.net:443 "POST /v3/sandbox024e4bcae7814311932f6e9569cea611.mailgun.org/messages HTTP/1.1" 200 138
INFO:__main__:Scrape complete and email sent.
2017-04-01 14:45:30 [__main__] INFO: Scrape complete and email sent.
Success!
2017-04-01 14:45:30 -- Completed task, took 11.00 seconds, return code was 0.
Was the email digest sent?
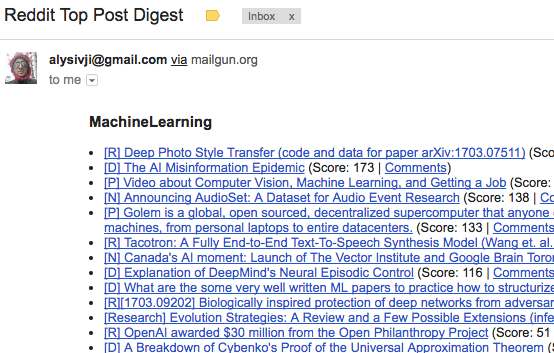
And we're done!
Conclusion
In this post, we refactored our Reddit Top Posts web scraper to automatically run on the PythonAnywhere cloud. Now that our data collection process is automated, we just have to monitor emails to ensure the script is working as intended.
Comments