Generating HTML Pages from MongoDB with MongoEngine and Jinja2 (Flask Part 1)
(Note: This post is part of my reddit-scraper series)
Summary
- Overview of MongoDB
- Discussion of Object-Relational Mapping (ORM)
- Use MongoEngine to get items out of MongoDB
- Render HTML pages using Jinja2
- Interact with REST API to send emails with Requests
Previously on Siv Scripts, we implemented a web scraping pipeline to store Top Posts scraped from Reddit into a MongoDB collection. The information we collected will become useful once it's out of the database so let's explore different ways of getting and using the data.
The obvious solution is to utilize a Python Web Framework to create a website that displays posts from various subreddits and allows users to mark items they have already seen. Based on our needs, Flask is the best tool for the job. Creating a Flask-based site requires that we familiarize ourselves with the Flask, its recommended design patterns, as well as the various extensions that enable us to create full-featured user experiences.
This will take a few posts to cover in depth so let's start at the beginning and explore how to generate HTML pages from MongoDB documents using the MongoEngine ORM and Jinja2 Templating Engine. We will then leverage the Requests library to send emails using MailGun's REST API; this will provide us with a temporary workaround to view scraped data until our Flask website is complete.
What You Need to Follow Along
Development Tools (Stack)
- Python 3
- MongoDB
- MongoEngine
- Jinja2
- Requests
- MailGun account
- Free account is limited to 10K emails per month, more than enough for our purposes
Code
MongoDB
In this section we will explore MongoDB, discuss best practices, and examine how it fits into our project.
Overview
"MongoDB is an open-source document database that provides high performance, high availability, and automatic scaling" (Mongo Docs).
What does this mean? In comparison to a relational database which focuses on linking data across tables with keys, a document database stores all the data elements together in one location.
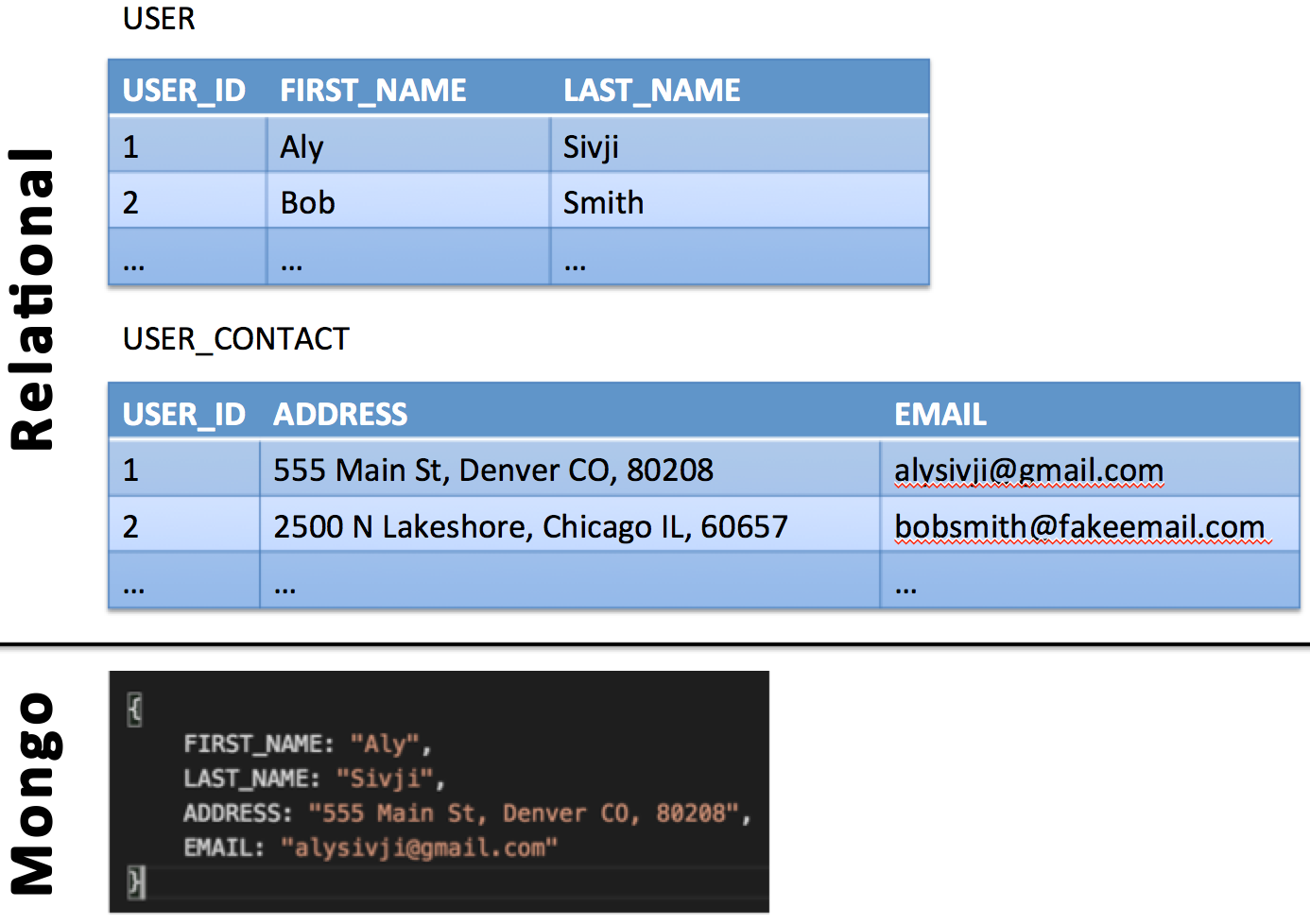
There are many reasons to use document-oriented databases over their relational counterparts. As our database will be the main data source for a variety of projects, it makes sense to use Mongo and take advantage of its flexible schemaless structure: our database can grow with the needs of our project.
Other reasons to use MongoDB:
- Rapid, agile development and deployment of web applications
- Fantastic documentation
- MongoDB has official drivers for all major languages
- MongoDB acquired WiredTiger and improved query performance
- Over 78K 'mongodb'-tagged questions on StackOverflow (Praise Be)
Technical Details
From the Mongo Docs:
A record in MongoDB is a document, which is a data structure composed of field and value pairs. MongoDB documents are similar to JSON objects. The values of fields may include other documents, arrays, and arrays of documents

MongoDB stores records as BSON (Binary-JSON) documents in collections and collections inside of databases (additional details).
When we send a query into Mongo, it performs a collection scan, i.e. it scans every document in our queried collection. This means that performance will become an issue as our data scales. To alleviate this, we can create indexes (single field, compound, multikey, or text) to ensure all calls to the database are quick.
We're glossing over a lot of the details here since database design and optimization is a field unto itself. While we are setting up our database, we will implement the following index strategy recommendations (from the MongoDB documentation):
- Create Indexes to Support Your Queries
- Use Indexes to Sort Query Results
- Ensure Indexes Fit in RAM
- Create Queries that Ensure Selectivity
MongoDB in Our Project
Loading Data
If you did not follow along the previous post, you can download the 20170309 data extract and import it into your instance of mongo using the following command:
$ mongoimport --db sivji-sandbox --collection top_reddit_posts --type json --file 20170309-reddit-posts.json
2017-03-09T15:14:51.021-0700 connected to: localhost
2017-03-09T15:14:51.043-0700 imported 551 documents
Document Schema
Let's use MongoDB Compass and take a look at a sample document to understand the fields we can pull.

The date_str field is a string version of the date field. Having a string type versus an ISODate type will make our queries run faster.
Creating Indexes
Following the best practices mentioned above, we should take some time to think about the queries we will need to run. Taking a step back, we need to consider the kinds of data we will want our website to display.

Use MongoDB Compass to create the index. Should look as follows:
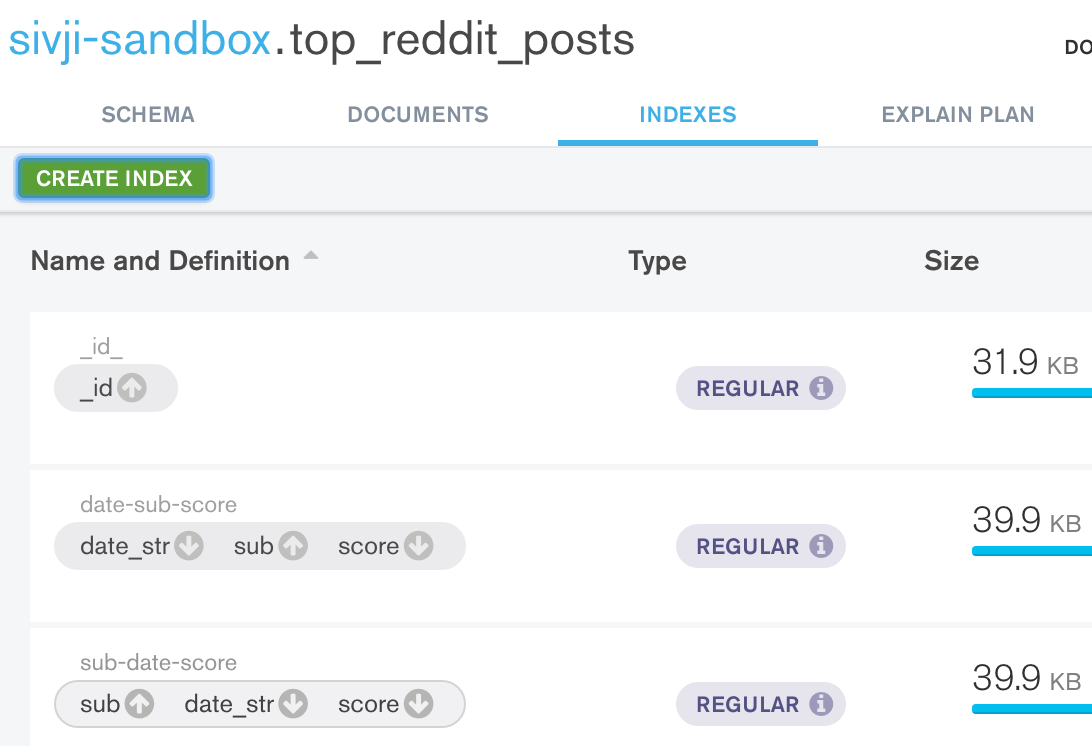
Our database is all set up and optimized. In the next section we will explore how to get data out of Mongo and into our program.
Note
- Adding score to the index will make our queries run faster, but the index will also take up disk space. This example is a bit trivial since it's a toy project, but we should get into the habit of thinking about tradeoffs.
Object-Relational Mapping (ORM)
Overview
Object-Relational Mapping (ORM) is a "technique that lets [us] query and manipulate data from a database using an object-oriented paradigm" (Source).
What does this mean? ORM libraries let us work with databases in the language of our choice. No more fumbling around with database connectors and SQL, we can treat objects in the database as objects in our program. More details can be found in this StackOverflow (Praise Be) discussion.
Like with all things in programming, there are people who consider ORMs to be anti-patterns. As long as we understand the limitations of using an ORM library (i.e. not a full replacement for querying languages), we can use them to get our projects off the ground quickly. As we scale up, we should revisit the use of an ORM.
ORM Libraries in Python
For relational databases, SQL Alchemy reigns supreme. PonyORM uses generators and lambdas (Author's Note: (☞゚ヮ゚)☞) to write its queries.
Since MongoDB is a document database, Object-Relational Mapping becomes Document-Object Mapping (DOM). MongoEngine and MongoKit are two popular DOM libraries. In the next section, we will use the MongoEngine library to pull data into our program from our instance of MongoDB.
MongoEngine
Using the tutorial and User Guide as a template, lets create a class to specify our schema.
# top_post_emailer/data_model.py
from mongoengine.document import Document
from mongoengine.fields import DateTimeField, IntField, StringField, URLField
class Post(Document):
''' Class for defining structure of reddit-top-posts collection
'''
url = URLField(required=True)
date = DateTimeField(required=True)
date_str = StringField(max_length=10, required=True)
commentsUrl = URLField(required=True)
sub = StringField(max_length=20, required=True) # subredit can be 20 chars
title = StringField(max_length=300, required=True) # title can be 300 chars
score = IntField(required=True)
meta = {
'collection': 'top_reddit_posts', # collection name
'ordering': ['-score'], # default ordering
'auto_create_index': False, # MongoEngine will not create index
}
Let's make sure this works by testing in the Python REPL.
$ python
Python 3.6.0 |Continuum Analytics, Inc.| (default, Dec 23 2016, 13:19:00)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.57)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from mongoengine.connection import connect
>>> from top_post_emailer.data_model import Post
>>> MONGO_URI = 'mongodb://localhost:27017'
>>> connect('sivji-sandbox', host=MONGO_URI)
MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True, read_preference=Primary())
>>> Post.objects()[0].title
'Chrome 56 Will Aggressively Throttle Background Tabs'
Looks good!
Notes
- The MongoEngine tutorial performs a wildcard import. PEP-0008 recommends that we stay away from this style of importing as to not clutter the namespace, which confuses both readers and many automated tools
- MongoEngine allows us to connect to multiple databases and use context-managers to switch between databases and collections (Author's Note: How Pythonic!)
- MongoEngine has a lot of built-in field types that we can use for validation checks
Jinja2
Jinja2 is a "modern and designer-friendly templating language for Python" that is the default templating engine bundled with Flask (additional info can be found in the Jinja docs).
What does this mean? Jinja2 lets us create templates with programming logic (control structures, inheritance) that can be rendered into HTML as the template code is evaluated. This will allow us to build dynamic, database-driven websites using Python! Real Python has a great primer on Jinja Templating.
Let's start with a basic template that will grab all the Top Posts from the last Reddit scrape.
<!-- top_post_emailer/template.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<title>Reddit Top </title>
</head>
<body>
<ul id="posts">
{% for selected_sub in Post.objects(date_str__gte=day_to_pull).distinct('sub') %}
<h3>{{ selected_sub }}</h3>
{% for post in Post.objects(date_str__gte=day_to_pull, sub=selected_sub) %}
<li><a href="{{ post.url }}">{{ post.title }}</a> (Score: {{ post.score }} | <a href=" {{ post.commentsUrl }}">Comments</a>)</li>
{% endfor %}
{% endfor %}
</ul>
</body>
</html>
We will need a way to render our Jinja2 template. Let's create a function:
# top_post_emailer/render_template.py
import os
import jinja2
def render(filename, context):
''' Given jinja2 template, generate HTML
Adapted from http://matthiaseisen.com/pp/patterns/p0198/
Args:
* filename - jinja2 template
* context - dict of variables to pass in
Returns:
* rendered HTML from jinja2 templating engine
'''
path = os.path.dirname(os.path.abspath(__file__))
return jinja2.Environment(
loader=jinja2.FileSystemLoader(path or './')
).get_template(filename).render(context)
Let's go back to our Python REPL and test to see if this works:
>>> from top_post_emailer.render_template import render
>>> ## get the last date the webscraper was run
... for post in Post.objects().fields(date_str=1).order_by('-date_str').limit(1):
... day_to_pull = post.date_str
...
>>> ## pass in variables, render template, and send
... context = {
... 'day_to_pull': day_to_pull,
... 'Post': Post,
... }
>>> print(render("template.html", context))
<!DOCTYPE html>
<html lang="en">
<head>
<title>Reddit Top </title>
</head>
<body>
... additional rows omitted ...
Great! In the next section we will email ourselves this information.
Note
- Once we start building out our Flask website, we can create complex Jinja templates with tables that have alternating row styles
Requests and MailGun API
Let's finish off this post by creating a minimum viable product (MVP): a program that emails us a list of all Top Posts scraped from our last Scrapy run. We will use Requests library to interact with MailGun's REST API to send HTML emails.
What can we say about Kenneth Reitz's Requests: HTTP for Humans that hasn't already been said? Nothing. Check the links for more info.
After a little Python, we come up with the following:
# top_post_emailer/mailgun_emailer.py
import os
import configparser
import requests
from requests.exceptions import HTTPError
def send_email(html):
'''Given HTML template, sends Reddit Top Post Digest email using MailGun's API
Arg:
html - HTML to send via email
Returns:
None
'''
## api params (using configparser)
config = configparser.ConfigParser()
config.read(os.path.join(os.path.abspath(os.path.dirname(__file__)), 'settings.cfg'))
key = config.get('MailGun', 'api')
domain = config.get('MailGun', 'domain')
## set requests params
request_url = 'https://api.mailgun.net/v3/{0}/messages'.format(domain)
payload = {
'from': 'alysivji@gmail.com',
'to': 'alysivji@gmail.com',
'subject': 'Reddit Top Post Digest',
'html': html,
}
try:
r = requests.post(request_url, auth=('api', key), data=payload)
r.raise_for_status()
print('Success!')
except HTTPError as e:
print('Error {}'.format(e.response.status_code))
# top_post_emailer/settings.cfg
[MailGun]
api = [Your MailGun API key here]
domain = [Your MailGun domain here]
Notes
- We used ConfigParser to keep our API keys secret. Check out PyMOTW's in-depth post about ConfigParser. (Author's Note: How awesome is the Python Standard Library?)
- Shoutout to this post showing how to send emails thru MailGun using Python
- The documentation for the Request library is really good. Go check it out. Also go check out the codebase. Very Pythonic.
- According to The Zen of Python: "Errors should never pass silently. Unless explicitly silenced." This means we should always try to have exception handling logic in our code. And when possible, FAIL LOUDLY. Found a great StackOverflow (Praise Be) discussion on how to handle exceptions in Requests
Putting it all Together
Now that we have all the pieces in place, we can finally write our script to get data out of Mongo and into a Jinja2 template. We can then use MailGun's REST API to send emails.
# top_post_emailer/__init__.py
from mongoengine.connection import connect
from .data_model import Post
from .render_template import render
from .mailgun_emailer import send_email
def email_last_scraped_date():
# connect to db
MONGO_URI = 'mongodb://localhost:27017'
connect('sivji-sandbox', host=MONGO_URI)
## get the last date the webscraper was run
for post in Post.objects().fields(date_str=1).order_by('-date_str').limit(1):
day_to_pull = post.date_str
## pass in variables, render template, and send
context = {
'day_to_pull': day_to_pull,
'Post': Post,
}
html = render("template.html", context)
send_email(html)
We have structured our app as a package and we need to create a script to run the application. First we will ensure that our directory structure looks as follows:
.
├── README.md
├── app.py
└── top_post_emailer
├── __init__.py
├── data_model.py
├── mailgun_emailer.py
├── render_template.py
├── settings.cfg
└── template.html
Now let's create our script:
# app.py
"""Script to pull and email last Reddit scape from MongoDB
"""
from top_post_emailer import email_last_scraped_date
if __name__ == '__main__':
email_last_scraped_date()
Run the app from the terminal with the following command:
$ python app.py
Success!
Did we receive an email?
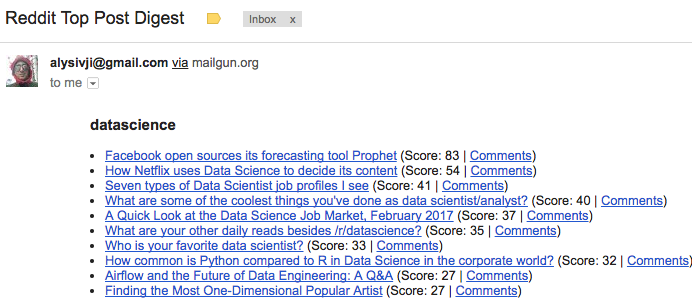
Notes
- This application is structured as a package, namely the
top_post_emailerpackage. Packages allow us to separate namespaces, increasing code modularity. I plan to examine this topic in a future post. For now, check out David Beazley's tutorial from PyCon2015.
Conclusion
In this post, we started to look into ways of getting data out of MongoDB and into the hands of our user. We decided to use the Flask framework and started getting our feet wet by generating HTML pages from items stored in our MongoDB instance using MongoEngine and Jinja2. Lastly, we wrote some code to email ourselves the HTML page we created using Requests and the MailGun REST API. This gave us a minimal viable product we can use until we get our Flask website up.
In a future post, we will build upon what we learned and deploy a basic Flask website.
Comments