Scraping Websites into MongoDB using Scrapy Pipelines
Summary
- Discuss advantages of using Scrapy framework
- Create Reddit spider and scrape top posts from list of subreddits
- Implement Scrapy pipeline to send scraped data into MongoDB
Wouldn't it be great if every website had a free API we could poll to get the data we wanted?
Sure, we could hack together a solution using Requests and Beautiful Soup (bs4), but if we ever wanted to add features like following next page links or creating data validation pipelines, we would have to do a lot more work.
This is where Scrapy shines. Scrapy provides an extendible web scraping framework we can utilize to extract structured data. If the website doesn't have an API, we can build a solution to parse the data we need into a format we can use.
I recommend the Scrapy tutorial from the documentation as an introduction into the terminology and process flow of the framework. This tutorial assumes some familiarity with Scrapy.
Acknowledgements: I used this Real Python post as a guide along with the latest version of Scrapy docs (v1.3).
Project Description
Author's Note: Always read the website's robots.txt file before writing a scraper. Be nice when making requests. Be nice in general. It's a good rule to live by.
Reddit provides a platform for communities to have deep discussions on very specific topics. To stay on top of news in my areas of interest, I frequent subreddits such as /r/peloton, /r/datascience, and /r/python. The Reddit voting system, along with the tendency of people to correct others, ensures that I won't have to spend a lot of time filtering information to get what I need.
If I can design and automate a process to generate weekly digests of my most visited subreddits, I can spend less time on Reddit and more time working on projects like this.
Process Outline
- Given a list of subreddits, scrape 'Top Posts'
- Build pipeline to store item in MongoDB
- Automate scraping and set up as CRON job or trigger function on Bluemix
- Design website to show scraped data stored in MongoDB
- Research into Angular2 vs Django/Flask
This will be the first in a series of posts that will create a fullstack solution to the workflow described above.
What You Need to Follow Along
Development Tools (Stack)
- Python 3
- Scrapy 1.3
- MongoDB
- Installed locally or use a service like MLab
- I will be using a local instance, but you can follow along with any Mongo URI
- PyMongo
Code
- Github Repo - Tag: blog-scrapy-part1
We can checkout the code from the git repository as follows:
$ git checkout tags/blog-scrapy-part1
Note: checking out 'tags/blog-scrapy-part1'.
Or we can use GitZip to download the tagged commit by URL.
Create Scrapy Project
We will utilize Scrapy's command line tools to initialize our project.
$ scrapy startproject reddit
$ cd reddit
The directory structure should look as follows:
.
├── scrapy.cfg # deploy configuration file
└── reddit # project's Python module
├── __init__.py
├── items.py # items definition file
├── middlewares.py
├── pipelines.py # project pipelines file
├── settings.py # project settings
└── spiders # dir to store spiders
└── __init__.py
File descriptions from Scrapy docs
Implement Crawler
Items to Scrape
Let's take a look at the all-time list of top posts from /r/peloton. Below is a screenshot with the items we want to scrape highlighted.
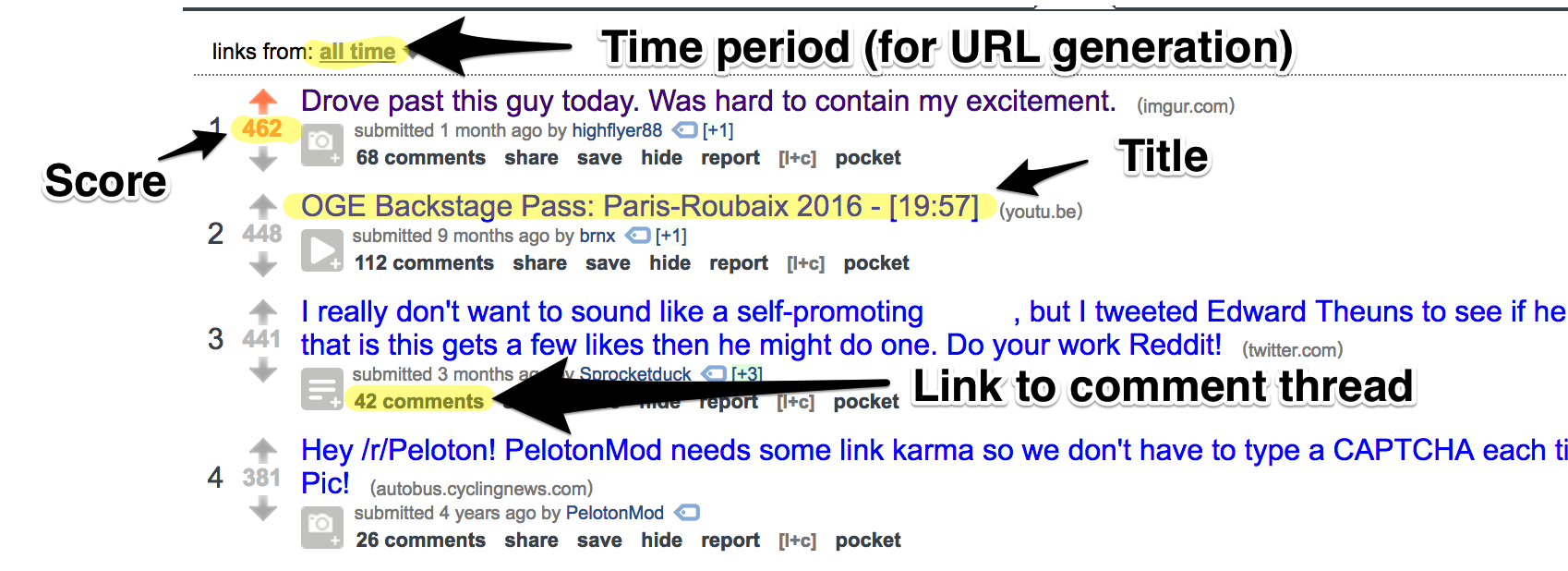
From this we can create our item template. We include some additional pieces of information (subreddit, date) to provide context.
# items.py
import scrapy
class RedditItem(scrapy.Item):
'''
Defining the storage containers for the data we
plan to scrape
'''
date = scrapy.Field()
date_str = scrapy.Field()
sub = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
score = scrapy.Field()
commentsUrl = scrapy.Field()
Create Spider
We will follow the template from the Scrapy docs to create the spider.
# spiders/__init__.py
from datetime import datetime as dt
import scrapy
from reddit.items import RedditItem
class PostSpider(scrapy.Spider):
name = 'post'
allowed_domains = ['reddit.com']
reddit_urls = [
('datascience', 'week'),
('python', 'week'),
('programming', 'week'),
('machinelearning', 'week')
]
start_urls = ['https://www.reddit.com/r/' + sub + '/top/?sort=top&t=' + period \
for sub, period in reddit_urls]
def parse(self, response):
# get the subreddit from the URL
sub = response.url.split('/')[4]
# parse thru each of the posts
for post in response.css('div.thing'):
item = RedditItem()
item['date'] = dt.today()
item['date_str'] = item['date'].strftime('%Y-%m-%d')
item['sub'] = sub
item['title'] = post.css('a.title::text').extract_first()
item['url'] = post.css('a.title::attr(href)').extract_first()
## if self-post, add reddit base url (as it's relative by default)
if item['url'][:3] == '/r/':
item['url'] = 'https://www.reddit.com' + item['url']
item['score'] = int(post.css('div.unvoted::text').extract_first())
item['commentsUrl'] = post.css('a.comments::attr(href)').extract_first()
yield item
The first part of the code defines the spider settings and tells Scrapy which URLs to parse (start_urls variable). Shoutout to list comprehensions!
The parse function defines how Scrapy will process each of the downloaded reponses (docs). We use CSS selectors to extract data from the HTML (more details in the Scrapy docs) before we yield items back to the framework using generators.
Notes
-
Generators are awesome because generators are Pythonic. If possible, try to
yieldvsreturn. David Beazley covered generators in his tutorial from PyCon 2014. Must watch for Pythonistas. -
If we want to grab the top 50 posts versus the top 25, we would need to modify the parse method to follow "next page" links and generate new
Requestobjects. More details can be found in the docs. -
Scrapy keeps track of visited webpages to prevent scraping the same URL more than once. This is yet another benefit of using a framework: Scrapy's default options are more comprehensive than anything we can quickly hack together.
Pipeline into MongoDB
Once an item is scraped, it can be processed through an Item Pipeline where we perform tasks such as:
- cleansing HTML data
- validating scraped data (checking that the items contain certain fields)
- checking for duplicates (and dropping them)
- storing the scraped item in a database
(from Scrapy docs - Item Pipeline)
We don't have any post-processing to perform so let's go ahead and store the data in a MongoDB collection. We will modify an example I found in the Scrapy docs and use Scrapy's built-in logging service to make things a bit more professional.
# pipelines.py
import logging
import pymongo
class MongoPipeline(object):
collection_name = 'top_reddit_posts'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
## pull in information from settings.py
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE')
)
def open_spider(self, spider):
## initializing spider
## opening db connection
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
## clean up when spider is closed
self.client.close()
def process_item(self, item, spider):
## how to handle each post
self.db[self.collection_name].insert(dict(item))
logging.debug("Post added to MongoDB")
return item
Configure Settings
Scrapy has a lot of settings for us to configure. We will be nice to Reddit and add a randomized download delay; this will ensure that we don't make too many requests in a short amount of time.
We also want to tell Scrapy about our MongoDB and ItemPipeline so it can import modules as necessary.
# settings.py
# ...
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = .25
RANDOMIZE_DOWNLOAD_DELAY = True
# ...
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'reddit.pipelines.MongoPipeline': 300,
}
MONGO_URI = 'mongodb://localhost:27017'
MONGO_DATABASE = 'sivji-sandbox'
# ...
Scraping Reddit Top Posts
We can now run the scraper using the following command from the scrapy project folder:
$ scrapy crawl post
2017-02-04 16:17:41 [root] DEBUG: Post added to MongoDB
2017-02-04 16:17:41 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.reddit.com/r/Python/top/?sort=top&t=week>
{'commentsUrl': 'https://www.reddit.com/r/Python/comments/5qwre9/is_wxpython_still_a_thing/',
'date': datetime.datetime(2017, 2, 4, 16, 17, 41, 166322),
'score': '24',
'sub': 'Python',
'title': 'Is wxPython still a thing?',
'url': '/r/Python/comments/5qwre9/is_wxpython_still_a_thing/'}
2017-02-04 16:17:41 [scrapy.core.engine] INFO: Closing spider (finished)
2017-02-04 16:17:41 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 1451,
'downloader/request_count': 5,
'downloader/request_method_count/GET': 5,
'downloader/response_bytes': 74227,
'downloader/response_count': 5,
'downloader/response_status_count/200': 4,
'downloader/response_status_count/301': 1,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2017, 2, 4, 21, 17, 41, 171132),
'item_scraped_count': 75,
'log_count/DEBUG': 156,
'log_count/INFO': 7,
'response_received_count': 4,
'scheduler/dequeued': 4,
'scheduler/dequeued/memory': 4,
'scheduler/enqueued': 4,
'scheduler/enqueued/memory': 4,
'start_time': datetime.datetime(2017, 2, 4, 21, 17, 39, 468336)}
2017-02-04 16:17:41 [scrapy.core.engine] INFO: Spider closed (finished)
We see the JSON objects that were scraped.
We can confirm the data was stored in the database using MongoDB Compass.
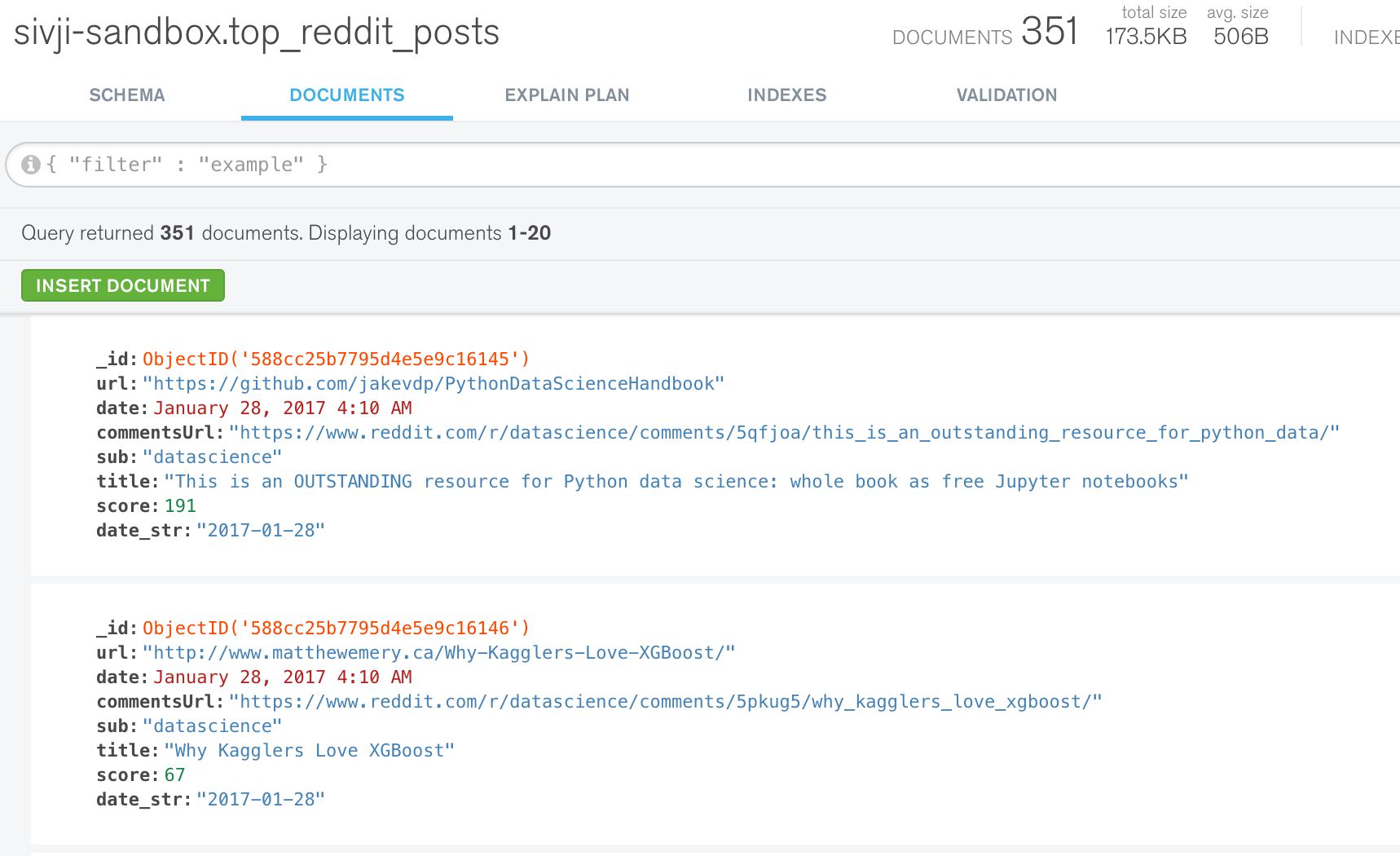
Looks good!
Conclusion
In this tutorial, we utilized the Scrapy framework to scrape Top Posts from Reddit into MongoDB. The above template can be modified to scrape any website we want. Yes, even Single Page Applications written in JavaScript!
I've been going out of my way to mention relevant documentation sections for each of the Scrapy modules I utilized. I did this for two reasons:
- To show how great the Scrapy docs are (kudos to the contributors)
- To emphasize that we should always look to the documentation when we get stuck.
It's easy to Google error messages and find relevant Stack Overflow (Praise Be) posts. However, we should always start our search for a solution in the documentation. Additionally, we can gain insights into best practices as described by the authors of the package.
What if the documentation we are using is awful or incomplete? Once we are done with our project, we should take the time to write better docs or a blog entry documenting our experience. Make it easier for the next person.
Python is great because of the community. Become part of the community and contribute wherever you can. It doesn't matter if you're a beginner, your help is always appreciated.
Next Steps
Future posts in this series will explore:
- sending an email digest of scraped data
- running Scrapy from a script
- deploying and scheduling the script to run on Python Anywhere
- building a REST API data access layer on top of MongoDB
- creating a front-end interface for users
- deploying front-end on Python Anywhere
- deploying front-end as a Cloud Foundary app on Bluemix
Updates
- 02/24: Added a field (date_str) to the top_reddit_posts collection to make indices more effective.
- 03/06: Fixed spelling and formatting
- 03/22: Added instructions on pulling tagged commit from Git repo
Comments